Yes, I was in Boulder, Colorado for my first in-person BBBT meeting.
First, what is the BBBT?
The BBBT was founded by Dr. Claudia Imhoff, an internationally known data warehousing and business intelligence expert who happens to live near Boulder, Colorado. I have known Claudia personal for many years. She did me the honor of critiquing and editing chapters int he very first book I wrote (and definitely made it better).

BBBT HQ Office in Boulder
The BBBT is a group of independent BI analysts, practitioners, authors, experts and consultants that gather periodically to learn about the various vendors and trends in this industry.
The group is by invitation from Claudia, and I was very honored to be asked to join this amazing group earlier this year.
Since I was heading to Denver for some other activities, I decided to go a bit earlier so I could attend the briefing with Denodo and surprise Claudia (since I usually just dial in from Houston). As a bonus I got to partake in some nice little treats Claudia had laid out for us.

Yum!
Who is Denodo?
So this week’s briefing was from Denodo Technologies. They are a privately held global company that provides modern data virtualization software. Here is a bit from their website:
Denodo Technologies, Inc. has redefined data integration to make the delivery of data to the corporate business applications simple.
The Denodo Data Services Platform is an enterprise Data Virtualization, Data Federation and Cloud Data Integration middleware that uses a declarative approach to abstract, unify, federate and understand disparate data sources and systems, supporting multiple acquisition and delivery modes and latency requirements, as well as a rich set of easy to use data transformation, data federation and data mashup capabilities.
Through Data Virtualization and Data Services, Denodo makes virtual data integration more flexible to adapt to the changing business needs and the evolution of the IT infrastructure, more universal to connect to a wider range of internal and external data sources, including the Web data, Cloud data, SaaS applications and less structured sources, and more cost-effective, by radically reducing licenses costs and the need for professional services and support.
Get the rest of the details about the company here.
Our in person presenters were Suresh Chandrasekaran, Senior VP, and Paul Moxon, Senior Director.

Denodo – Suresh presenting
One key phrase they use is Broad Spectrum Capabilities. Here is a tweet with a nice picture of what they meant by that:
Capabilities of the @denodo #data platform #BBBT pic.twitter.com/UEoIcQOs26
— Jorge García (@jgptec) December 13, 2013
Data Virtualization
Everyone has their own take on what “data virtualization” means. Here is one slide showing what Denodo means:

Pretty broad based definition overall but it definitely set the context for the discussion. Being a Data Warrior, I am particularly interested in their Common Data Layer (alternatively called a Data Services Layer). Basically they allow you to map any data from nearly any source (and type of source) to what I would call a logical canonical model.
Not easy by any means, but I was reasonably impressed with what I saw of their data modeling tool where you defined not only the logical definition of the “entity” but also defined where that data came from and how it was joined to other sources for virtual integration.
One key point that people need to remember is that even with an easy to use, web-based, graphical tool for defining these virtualized data objects, somebody, somewhere, still has to do the very hard work of determining how this data joins together. That is hard enough to do when you are joining relational tables, but it does not get any easier when you throw in NoSQL, unstructured or semi-structured data streams, JSON documents, etc from sources like Cloudera and MongoDB (to name only a very few).
While I have not used the Denodo tool myself, their data modeling and mapping tool did look fairly easy to use and navigate.
Virtualization Patterns
One unique thing Denodo has done is define a variety of patterns they have observed with their clients. In turn they have developed best practices and solutions for implementing those patterns efficiently with their tool (of course).
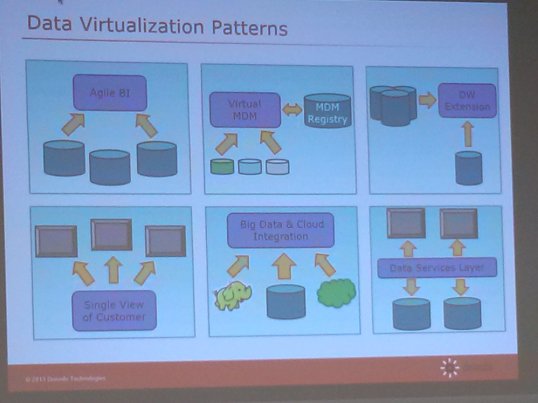
Virtualization Patterns
While Agile BI and Data Warehousing are amoung the patterns, they are not the only ones.
This is good and progressive thinking (IMO). Most organizations really have a need for more than one of these patterns to truly solve their modern data management issues. There are many sources and uses of data in the modern data landscape and thinking that addressing only one of these (for example BI) will solve your issues, is thinking too much “inside the box”.
I am pleased to see a vendor taking this broad-based view of the situation and working to provide a unified solution platform to help.
So if you are looking/considering building a data services architecture and are looking at data virtualization tools, I would recommend you at least consider Denodo.
And of course stay tuned to the BBBT, and check the archived podcasts to see what other interesting vendors there are out there that you might want to consider.
Keep learning!
Kent
The Oracle Data Warrior
Posted in
BBBT,
Data Warehouse and tagged
#BBBT,
BI,
business intelligence,
Claudia Imhoff,
data integration,
data virtualization,
data warehouse solution,
data warehousing,
denodo,
Denodo Technologies |












You must be logged in to post a comment.