A few weeks back, right after attending Snowflake Summit, I had the pleasure of chatting with Sanjeev Mohan on his podcast – It Depends. We spent an hour or so chatting about trends in modern data management, data mesh, data vault, my now semi-retired life as an advisor to several Snowflake partners, and my love of martial arts.
Please join me on March 30th at 11AM CDT for my first official post-retirement talk!
I will be chatting with Mike Lampa from Great Data Minds about my career and plans post-Snowflake. I expect we will cover a wide range of topics including what community and technical evangelism is all about, as well as what made me jump from nearly 30 years in the Oracle world to a small startup with less than 100 people that claimed to have re-invented data warehousing in the cloud.
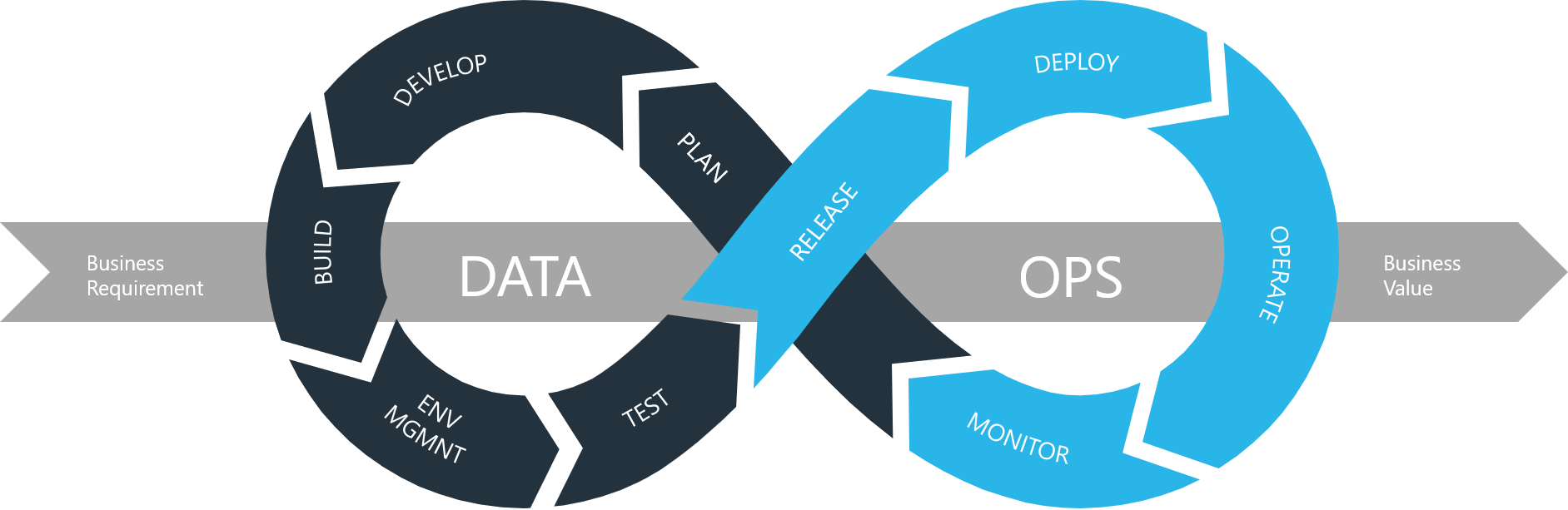
LONDON, Feb. 16, 2022 /PRNewswire/ — DataOps.live, the London-based software company dedicated to helping organisations to build and manage their essential data applications and data products more effectively, is delighted to announce that Kent Graziano has joined its Advisory Board with immediate effect.
Could not resist staying out of the fray! I have worked with these folks from their earliest days as a Snowflake SI partner, and now as a software partner that supports the Snowflake Data Cloud. I am looking forward to helping Justin and Guy in the next stage of evolving the DataOps.live platform towards the vision of #TrueDataOps.
Shortly before leaving Snowflake last year, I was interviewed for this post about one of the worst case examples of data siloes I had seen – we called them data puddles!
A few years ago, Kent Graziano joined a big organization to work on its data. The first problem was that nobody really knew what and where all the data was. Graziano took his first three months on the job investigating data sources and targets, ultimately creating an enterprise data map to illustrate all the flows. It wasn’t pretty.
“In the end, I discovered that the same data was being sent to three or four places,” he said. In one case raw data was transformed and stored in a data warehouse, then moved from there into another warehouse—which was also pulling in the original raw data.
Graziano, who recently retired from his post as Chief Technical Evangelist at Snowflake, said this scenario is entirely common. Data scattered and copied in lakes, warehouses, data marts, SaaS platforms, spreadsheets, test systems, and more. That’s mass data fragmentation, or, more colloquially, data sprawl or data puddles.
Indeed, 75% of organizations do not have a complete architecture in place to manage an end-to-end set of data activities including integration, access, governance, and protection, according to IDC’s State of the CDO research, December 2021. This lack of governance combines with legacy systems, shadow IT, and good intentions to pave the road to a lot of fragmentation.
Check out the rest of the post to learn how data sprawl hurts businesses and what to do about it. Read it all here!
After six years and one month as the global evangelist for Snowflake (and almost 40 years in IT), I’ve decided to slow down and begin easing into retirement. As such, today is my last day at Snowflake.
I loved the Snowflake product so much that I gave up independent consulting to sign on (as employee 105) with this scrappy little startup in Silicon Valley (my first) and take a chance. Now at the end of 2021, the product is even more amazing than when I started and with #TheDataCloud it is changing the world of data.
The people and culture established by the founders, Benoit and Thierry, along with the leadership of Bob Muglia, Denise Persson, Chris Degnan, and Frank Slootman, have made this the best job (and longest) of my career. I cannot imagine a better way to bring this chapter to an end.
Thank you, Benoit and Thierry, for your vision and for inventing a new architecture for databases.
Thank you, Kyle Rourke and Todd Beauchene for introducing me to this amazing technology at that tiny meetup in Denver. Know you changed my life!
And finally, thank you Francis Mao for your incredible artwork (above) and especially for my Data Superhero uniform and avatar. The #DataWarrior never looked better!
It has been an honor and a pleasure to work with Snowflake from startup thru hypergrowth to the largest software IPO in history! What a wild and adventurous ride it has been. And I know the team will continue to go far and continue to disrupt the way we manage and get value from data long into the future (I am counting on it…after all I am a shareholder too!).












You must be logged in to post a comment.