Schema-on-what? How to model JSON
It seems hard to believe, but all year, around the world, I continue to have this conversation on whether or not we still need data modeling.
I know! Crazy!
Thought we were past that…
As I have said before,
Schema-on-read has the word SCHEMA in it!
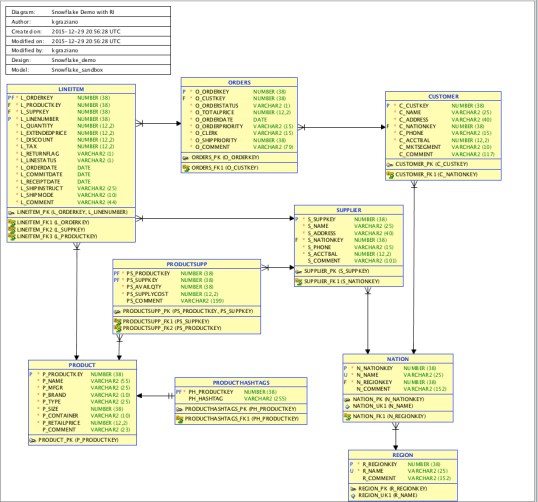
So instead of continuing to rant about it, I decided to put together a talk to show people, graphically, what I meant by decomposing, step by step, a few JSON documents into real data models. For the sake of the talk I decided to go with 3NF and Data Vault styles to make my point.
This talk has been very well received so I decided I would share it a bit more publicly by posting it here on my blog.
Now that you can see how to model JSON, check out my Snowflake ebook on how to easily analyze JSON using SQL.
If you know any meet-ups or conferences that I should be giving this talk at, please let me know. Or check out my speaking schedule for 2019 and join me at one of the events already on my calendar. (1st up is ITOUG in Milano!)
Ciao!
Kent
The Data Warrior & Chief Evangelist at Snowflake
P.S. There was no magic, or built-in wizard, to creating the models. I did it all by hand using Oracle Sql Developer Data Modeler.









You must be logged in to post a comment.