Tech Tip: Connect to Snowflake db using #SQLDevModeler
So, some of you may have noticed that I took “real” job this week. I am now the Senior Technical Evangelist for a cool startup company called Snowflake Computing.
Basically we provide a data warehouse database as a service in the cloud.
Pretty cool stuff. (If you want to know more, check out our site at snowflake.net)
I will talk more about the coolness of Snowflake (pun intended) in the future, but for now I just want to show you how easy it is to connect to.
Of course the first thing I want to do when I meet a new database is see if I can connect my most favorite data modeling tool, Oracle SQL Developer Data Modeler (SDDM), to it and reverse engineer some tables.
The folks here told me that tools like Informatica, MicroStrategy, and Tableau connect just fine using either JDBC or ODBC, and that since we are ANSI SQL compliant, there should be no problem.
And they were right. It was almost as easy as connecting to Oracle but it was WAY easier than connecting to SQL Server.
First you need a login to a Snowflake database. No problem here. Since I am an employee, I do get a login. Check.
We have both a web-UI and a desktop command line tool. Turned out I needed the command line tool which incidentally needed our Snowflake JDBC connector to work. Followed the Snowflake documentation, downloaded the JDBC drive (to my new Mac!). Piece of cake.
So connecting from SDDM is really easy. First add the 3rd party JDBC driver in preferences. Preferences ->Data Modeler -> Third Party JDBC Driver (press the green + sign, then browse to the driver).

As you can see our JDBC driver is conveniently named snowflake_jdbc.jar.
Next step is to configure the database connection. To do this you go to File -> Import -> Data Dictionary, then add a new connection in the wizard.
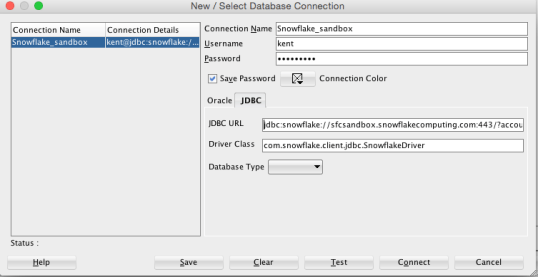
Give at a name and login information, then go to the JDBC tab.
So getting the URL was the trick (for me anyway). Luckily the command line tool displayed the URL when I launched it in a terminal window, so I just copied it from there (totally wild guess on my part).
So the URL (for future reference) is:
jdbc:snowflake://sfcsandbox.snowflakecomputing.com:443/?account=<service name>&user=<account>&ssl=on
Where account is whatever you named your account in Snowflake (once you have one of your very own that is).
The driver class was a little trickier – I had to read our documentation! Thankfully it is very good and has an entire section on how to connect using JDBC. In there I found the drive class name:
com.snowflake.client.jdbc.SnowflakeDriver
That was it.
I pushed the Test button and success!
Now to really test it, I did the typical reverse engineer and was able to see the demo schema and tables and brought them all in.
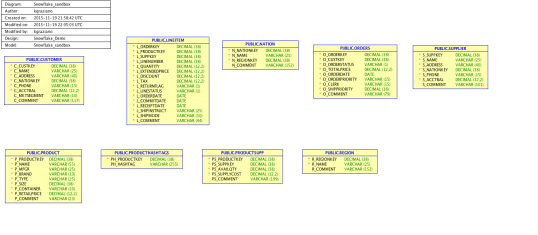
Demo schema in Snowflake (no, not a snowflake schema!)
So I call that a win.
Not a bad weeks work really:
- New job orientation
- Start learning a new tech and the “cloud”
- Got logged in
- Installed SDDM on a Mac for the 1st time ever!
- Configured to speak to an “alien” database
- Successfully reverse engineer a schema
- Blog about it.
So that was my 1st week a a Senior Technical Evangelist.
TGIF!
Kent
still, The Data Warrior
P.S. If you want to see more about my week, just check my twitter stream and start following @SnowflakeDB too.









You must be logged in to post a comment.