Tips for Optimizing the #DataVault Architecture on #Snowflake (Part 2)
SETTING UP FOR MAXIMAL PARALLEL LOADING!
In this post, I discuss how to engineer your Data Vault load in Snowflake Cloud Data Platform for maximum speed.
Because Snowflake separates compute from storage and allows the definition of multiple independent compute clusters, it provides some truly unique opportunities to configure virtual warehouses to support optimal throughput of DV loads.
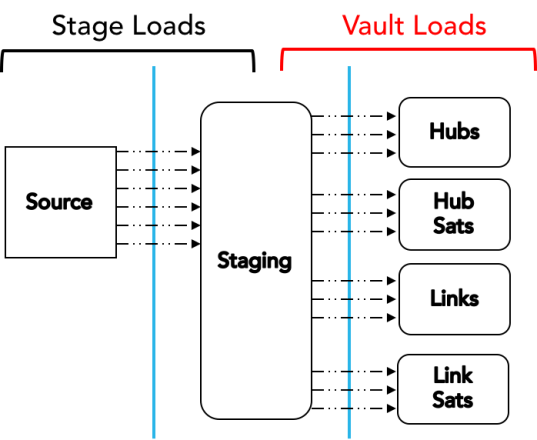
Along with using larger “T-shirt size” warehouses to increase throughput, using multi-cluster warehouses during data loading increases concurrency for even faster loads at scale.
Get the details – Tips for Optimizing the Data Vault Architecture on Snowflake (Part 2)
Enjoy!
Kent
The Data Warrior & Chief Technical Evangelist for Snowflake








