Early Christmas: The New #SQLDev Data Modeler is Here!
Thanks to the gang at Oracle for an early Christmas present – the newest version of Oracle SQL Developer Data Modeler (SDDM) is ready for download and use.
The best FREE data modeling tool on the planet just got better!
To be clear this is Early Adopter (EA) version 2 of SDDM 4.2. You can get it here right now!
#SQLDev Data Modeler New Features
Of course there are some bug fixes from EA1, but also some new features for you to enjoy:
Import from Oracle Database
- performance and filtering enhancements
- ability to define Oracle Client for thick connections
- view and materialized view driving query and columns now parsed and validated
Versioning
- improvements in performance
- new models are shown as a single node in pending changes window
Reporting
- PDF reports allow diagrams to be embedded with links from diagram to details part into report
- HTML report for tables now include diagrams
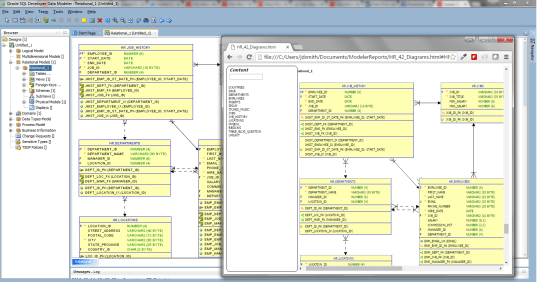
#SQLDev Data Modeler HTML report with diagrams embedded
So go download and unwrap that present!
Cheers!
Kent
The Data Warrior
P.S. If you need training on Oracle Data Modeler, be sure to check out my online video training course along with my tips and tricks ebook. (HINT: Buy them now, and you may be able to deduct the cost from your 2016 taxes as an educational expense.)









You must be logged in to post a comment.